datax性能优化
架构图:
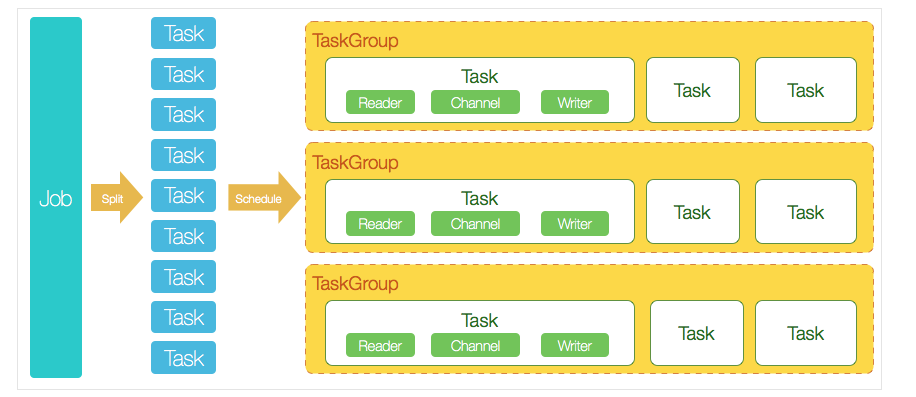
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX
Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。 - DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务)
,以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3.切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)
。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4.每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5、DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
简单总结过程如下:
一个DataX Job会切分成多个Task,每个Task会按TaskGroup进行分组,一个Task内部会有一组Reader->Channel->
Writer。Channel是连接Reader和Writer的数据交换通道,所有的数据都会经由Channel进行传输
优化1:提升每个channel的速度
DataX内部对每个Channel会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是1MB/s,可以根据具体硬件情况设置这个byte速度或者record速度,一般设置byte速度,比如:我们可以把单个Channel的速度上限配置为5MB
**优化2:提升DataX Job内Channel并发数 并发数=taskGroup的数量每一个TaskGroup并发执行的Task数 (
默认单个任务组的并发数量为5) **
提升job内Channel并发有三种配置方式:
- 配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速
- 配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速
- 直接配置Channel个数.
配置含义:
job.setting.speed.channel : channel并发数
job.setting.speed.record : 全局配置channel的record限速
job.setting.speed.byte:全局配置channel的byte限速
core.transport.channel.speed.record:单channel的record限速
core.transport.channel.speed.byte:单channel的byte限速
第一种方式举例如下:core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,所以Channel个数 =
全局Byte限速 / 单Channel Byte限速=5242880/1048576=5个,配置如下:
1 | { |
第二种方式举例如下:core.transport.channel.speed.record=100,job.setting.speed.record=500,所以配置全局Record限速以及单Channel
Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速=500/100=5
1 | { |
第三种配置举例如下:直接配置job.setting.speed.channel=5,所以job内Channel并发=5个
1 | { |
- 当提升DataX Job内Channel并发数时,调整JVM堆参数,原因如下:
1 | - 当一个Job内Channel数变多后,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。 |
Channel个数并不是越多越好, 原因如下:
```
- Channel个数的增加,带来的是更多的CPU消耗以及内存消耗。
- 如果Channel并发配置过高导致JVM内存不够用,会出现的情况是发生频繁的Full GC,导出速度会骤降,适得其反。这个可以通过观察日志发现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
测试使用datax从mysql到mysql,不同配置测试效果如下:
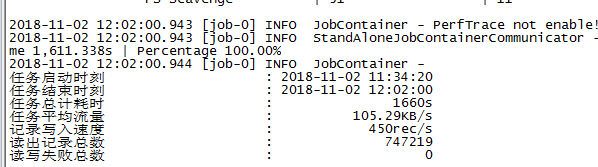
使用默认单个channel 限速1M/s,测试情况如下,1660s跑完:
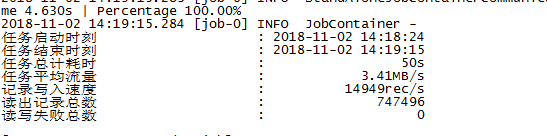
使用单通道,5M/s,测试情况如下,50s跑完:
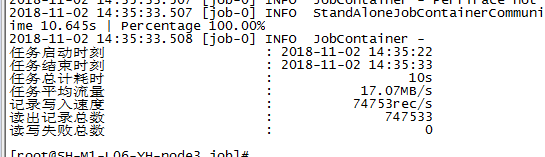
使用5通道,5M/s,测试情况如下,10s跑完:
**注意:**
MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能,splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据,第三个测试不配置splitPk测试不出来效果
调优没有固定的,先了解原理,再根据原理及执行过程进行局部或者全局的调优
#### 定时增量同步
相比全量同步,增量同步增加了用某个字段来判断改条数据是否被更新,具体体现在 Shell 脚本和 Json 文件中,下面会提到。
###### 1.准备工作:
给需要同步的表增加用于增量同步判断的字段,可用ID也可以用时间,个人建议用时间,更方便。
给读库的table1表加上实时更新的时间记录字段(可根据需要是否给写库也加上,我这里是加上的):
```sql
alter table table1 add column `curr_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间(DataX数据采集使用)';
1
- Channel个数的增加,带来的是更多的CPU消耗以及内存消耗。
具体可参考我的其他博客的第二点:MySQL | 设置时间字段为自动更新(CURRENT_TIMESTAMP).
1 | !/bin/bash |
至于为什么加. /etc/profile
,参考此文章的第二点:DataX踩坑2: | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
3.示例Json文件(相比于全量同步,这里使用了在读库(reader)加了一个where条件,条件就是传入的当前日期):incr_table1.json
1 | { |
简单说一下上面的增量逻辑:在 Shell
脚本中传入当前日期给where条件时间,我会让定时器在凌晨五点执行,所以查询的是昨天凌晨5点到今天04:59:
59有修改的数据,查询条件就是第1点说到的实时修改时间
4.添加定时器,这里使用的是crontab
运行脚本之前先将放入的脚本进行授权,否则不能执行,对文件进行最高级别授权命令:
1 | chmod 777 incrSyncTask.sh |
4.1.编辑定时任务crontab,使用以下命令进入crontab任务文件:
1 | crontab -e |
4.2.进行vi编辑即可,添加crontab定时任务(每天凌晨5点执行,跟cron表达式类似):
1 | 0 5 * * * /opt/datax/bin/incrSyncTask.sh >/dev/null 2>&1 |
建议加上>/dev/null 2>&1,因为crontab会把日志都发给mail,这里是直接丢弃一样
,也可以指定输出到某个文件中,参考如下命令,每天执行后生成日志文件:
1 | 0 5 * * * /opt/datax/bin/incrSyncTask.sh > /opt/datax/log/incrSyncTask_$(date +\%Y\%m\%d).log 2>&1 |
这里需要用斜杠”"对百分号进行转义
4.3.查看crontab日志:
1 | tail -f /var/log/cron |
如果找不到/var/spool/mail/root
文件,参考:DataX踩坑2: | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
定时任务跑了之后,会将日志文件输出到上面的位置,根据登录宿主机的用户不同,文件名不同。这里的发送到邮箱有些坑,日志量过大问题、找不到邮箱问题,参考:DataX踩坑2 | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
三、注意点
1.关于脚本运行后连接数据库报连接失败,重新连接等错误(\r换行符的问题)
其实脚本中的所有数据库参数都是正确的,但就是报错,可以看日志,发现每个参数后面都携带了\r换行符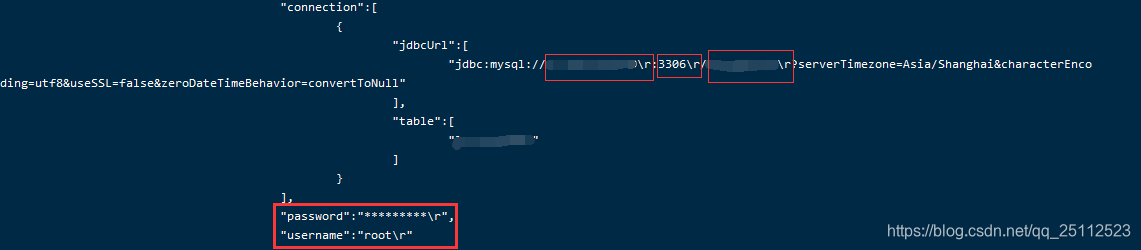
解决方法:Shell 脚本参数传递时有 \r 换行符问题.
2.批量执行多文件命令报错
建议将speed中的channel参数设置大一点,如10。
由于DataX读取数据和写入数据需要占用服务器性能,所以需要考虑服务器性能,channel的值并不是越大越好。
具体可参考结尾的性能优化文章。
3.执行命令报:FileNotFoundException
本来想将全量同步 Json 文件和增量同步 Json 文件放入不同的文件夹A和B,便于区分,直接放在 DataX 安装路径的 job 目录中,结果执行命令时找不到
job 目录下的A、B文件夹中的Json文件
4.定时任务crontab不执行 或 报错:/bin/sh: java: command not found
参考文章:DataX踩坑2: | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
__END__